In my first attempt to create an Azure Data Factory job, I used compute resources in Azure that are managed by Data Factory itself. Alternatively, you can use a self-hosted integration runtime to make use of compute resources elsewhere – such as your own on-premise environment.
In this example, I install a self-hosted integration runtime within my own on-premise environment (which is just my laptop!), and create a Data Factory job to extract content from a table hosted on a SQL Server instance running on that same laptop.
Creating the self-hosted integration runtime
To do this, you must open Azure Data Studio, select the “Manage” toolbox icon from the left-hand menu, “Integration runtimes” from the “Connections” list, and then “+ New”.

The “AutoResolveIntegrationRuntime” that you can see present already is the Data Factory-managed Azure resource that I used for the previous copy data pipeline.
Choose “Azure, Self-Hosted”

Of the options that then appear, I am going to select “Self-Hosted” to try and install the integration runtime on my laptop.


Copy and paste one of the Authentication Keys that appear (store them somewhere that you can access later). Then click “Download and install integration runtime”

You’ll be taken to a page of the Microsoft Download Centre, where you can choose from a few recent versions of the integration runtime installer.

Once the .msi file has downloaded to your local machine, open it and run through the installation wizard.

Paste the authentication key that you saved earlier into the registration page shown below:

The “Integration Runtime (Self-hosted) node name” that appears below should be the name of the local machine that you installed the integration runtime on (my company laptop is named “DATAMINISTER”)

Click “Finish” to complete the registration.

You now have a new integration runtime (IR) to choose within Data Factory Studio:

Test out the self-hosted IR with a new pipeline
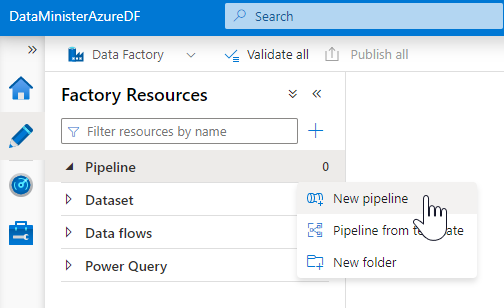
Check that the new IR can be used successfully in a Data Factory pipeline by opening up Azure Data Factory Studio, and selecting “New pipeline” from “Factory Resources”.

Create a “Copy data” activity…

Within that copy data activity, create a new source dataset connection, with a type of “SQL Server”. This will be configured to connect to a SQL Server instance on the same server that the self-hosted IR was created on.


Fill in the details of your on-premise SQL Server instance, and the database within that instance that you want to extract data from.
In the “Connect via integration runtime” dropdown, you can select the self-hosted IR that you’ve just created.
You’ll need to provide an authentication method too…

In the above, I’m using a SQL account to connect to the source database. The success of the connection will rely upon the SQL account having adequate access to the database.
Checking the account’s credentials within SQL Server Management Studio (SSMS) shows that the “DataFactory_Reader” user has read access within the “AdventureWorksDW2017” database.

Back in Azure Data Factory Studio, if the Linked Service you’ve just set up is working OK you should be able to see individual tables under the “Table name” dropdown, within the “Connection” section of the Linked Service.

Back on the “Source” tab of the “Copy data” task for the pipeline, you can enter your own SQL query to just extract a few named columns from the table you’ve specified in the connection above.

You can even “Preview data” to check this is working:

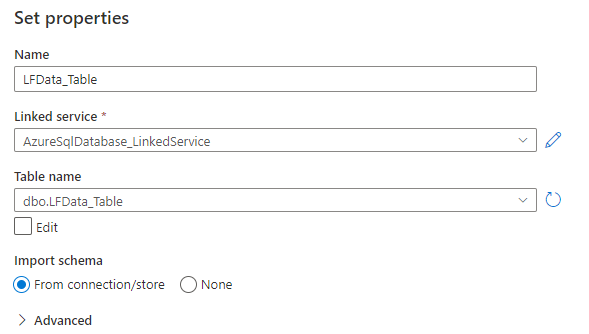
With the connection to the source database created, you now need a destination database to transfer data to. I am going to use a new table within the same “DataMinister_DB” that I created in this previous blog.
To create the new table, I opened a Query Editor session against the database within the Azure portal, and created a simple table (that has a schema matching the data I’ve selected with my query, which extracts three columns from the source database).


Within the “Sink” tab, I specify a connection to this new table:


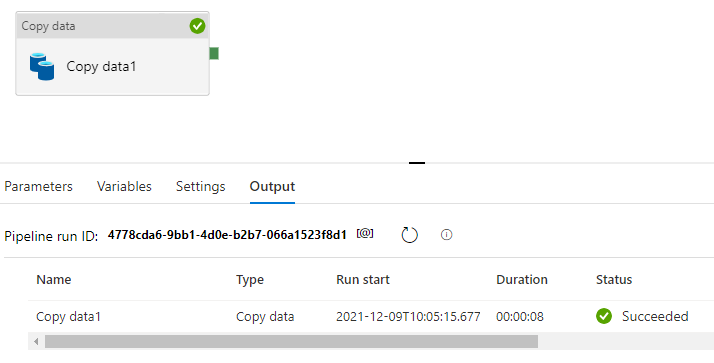
Now that I’ve configured the source and destination databases/tables for the “Copy data” activity, I can run “Debug” within Azure Data Factory Studio to check it works OK…

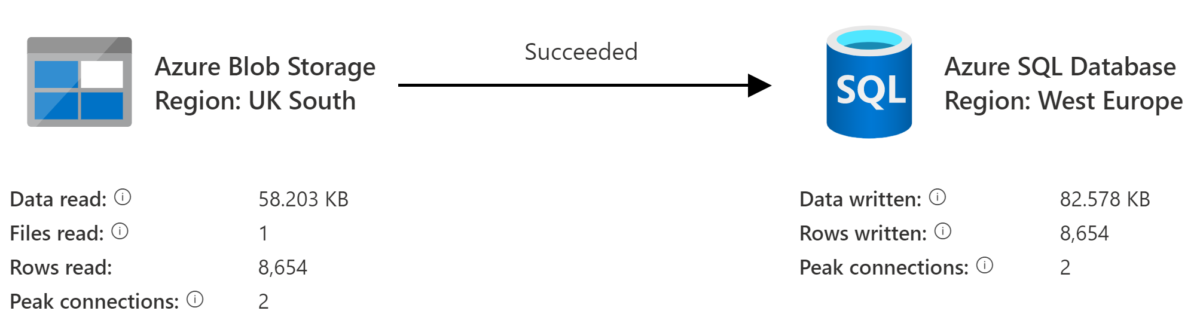
…and it does! Note that the integration runtime used was the self-hosted IR that I created at the start of this article.

120 rows of data have been copied from the on-premise database hosted upon my laptop, to the Azure SQL Database that I created within the cloud.
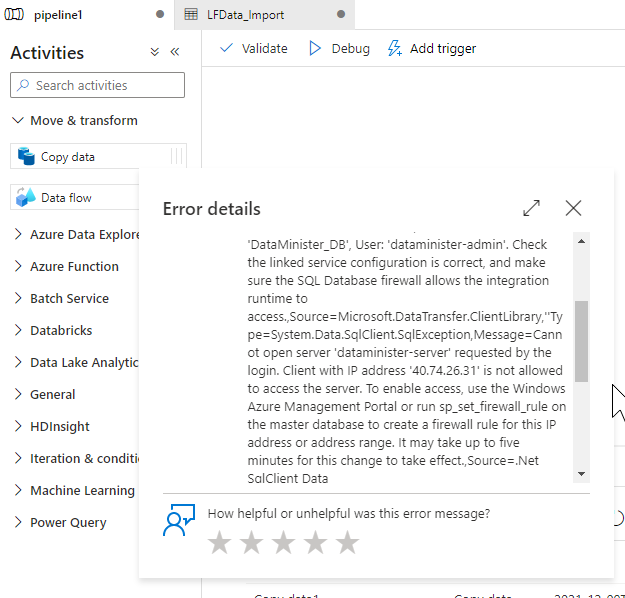
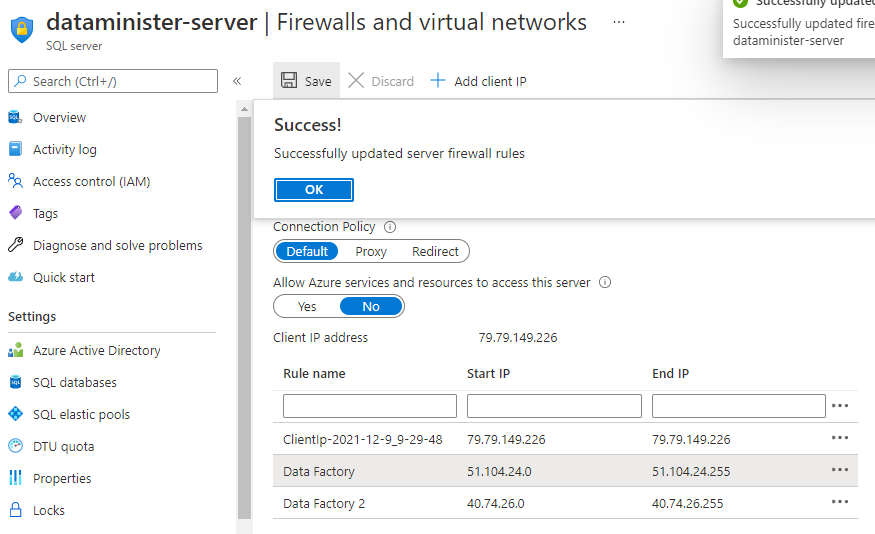
It’s worth noting that this process succeeded first time for me because I’d already added several IP addresses that Data Factory uses to the “approved” IPs list for the destination database (while I was running through the steps in this post). If you haven’t followed the steps within that post first, you may get a few connection errors when trying to connect to the Azure database. The post shows how you can overcome these errors by “approving” the IP addresses.